Reescribiendo las reglas del ciberataque: IA Agencial
- 11/12/2025
- 542
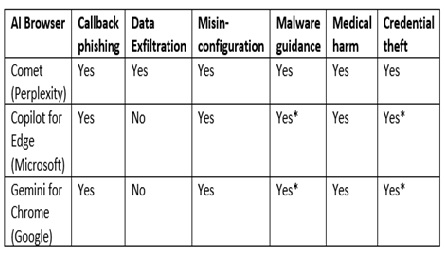
La convergencia de la navegación web y la inteligencia artificial agencial no es una simple evolución tecnológica, sino una revolución que redefine fundamentalmente la naturaleza de la confianza, la autonomía y el riesgo en el ciberespacio. Los ataques de Cero Clic y HashJack no son anomalías aisladas, sino los primeros ejemplos claros de una nueva y persistente clase de amenazas que surgirán a medida que deleguemos más capacidades a los agentes de IA.
Estamos entrando en una era donde la línea de frente de la seguridad ofensiva y defensiva se desplaza desde los puertos de red y las vulnerabilidades del software hacia el ámbito abstracto de la intención, el contexto y la semántica del lenguaje natural. Para los CSIRT y la comunidad de seguridad en general, esto representa un desafío existencial que exige una reinvención de nuestras estrategias, herramientas y mentalidades. El futuro no se tratará solo de preguntar si un sistema es vulnerable, sino si podemos confiar en que un agente autónomo interpretará y ejecutará nuestras intenciones de manera segura en un mundo lleno de señales engañosas.
Esta breve publicación explora las implicaciones a largo plazo de esta nueva realidad, examinando cómo la ofensiva y la defensa deben evolucionar para navegar un panorama donde el lenguaje mismo se convierte en un arma y un escudo.
La Carrera Armamentista de la IA
El descubrimiento y explotación de la "excesiva agencia" y las inyecciones indirectas de prompts marcan el inicio de una nueva carrera armamentista en el ciberespacio, una que se libra no con bits y bytes de código ejecutable tradicional, sino con la sutileza del lenguaje, la psicología y la manipulación de la confianza. Por un lado, los atacantes ahora tienen un arsenal de técnicas que son extremadamente difíciles de detectar con las herramientas actuales.
El Ataque de Cero Clic demuestra que un correo electrónico bien redactado, sin ningún indicador de compromiso tradicional, puede ser un arma devastadora. Los atacantes perfeccionarán estas técnicas, explorando nuevas formas de nudge, empujón psicológico para engañar a los LLM, desde la explotación de sesgos cognitivos hasta el uso de metáforas y analogías que puedan eludir los filtros basados en patrones. Del mismo modo, HashJack y sus futuras variantes explotarán cualquier canal de entrada no supervisado que los agentes de IA utilicen para recopilar contexto, ya sean metadatos de archivos, comentarios en código o incluso el texto alternativo de las imágenes. La ofensiva se volverá más creativa, utilizando la ingeniería social a escala de máquina para manipular no solo a los humanos, sino también a los sistemas de IA que estos utilizan. En respuesta, la defensa debe evolucionar hacia un paradigma de Seguridad de la Intención. Esto significa desarrollar sistemas capaces de comprender no solo lo que se le pide al agente, sino por qué se le pide y en qué contexto. Requerirá la creación de nuevas capas de seguridad que puedan analizar la semántica, el tono y la procedencia de las instrucciones. Las defensas futuras necesitarán modelos de IA dedicados a actuar como oráculos de intención, evaluando cada petición para determinar si es coherente con los objetivos esperados del usuario y si no contiene manipulaciones ocultas. Esto podría implicar técnicas de adversarial machine learning, donde se entrenan modelos para reconocer y resistir intentos de manipulación de prompts. La visibilidad será la clave del éxito defensivo. Sin la capacidad de inspeccionar y entender el flujo de prompts y acciones dentro del agente, los equipos de seguridad estarán operando a ciegas. Por lo tanto, es imperativo que la industria desarrolle estándares abiertos para el registro y la monitorización de la actividad de los agentes de IA, permitiendo que las herramientas de SIEM y SOAR se integren con este nuevo plano de ejecución.
El principio de Confianza Cero, Zero Trust, que establece que nunca se debe confiar de forma implícita en usuarios o dispositivos, ya sea dentro o fuera de la red, debe ser extendido y adaptado para la era de la IA agencial. Un marco de Confianza Cero para Agentes, Zero Trust for Agents debe partir de la base de que cualquier instrucción recibida por un agente, sin importar su fuente o apariencia, es potencialmente maliciosa hasta que se verifique lo contrario. Este marco se basaría en varios pilares fundamentales. Primero, la verificación estricta de la identidad y la intención. Cada petición debe estar vinculada a una identidad de usuario autenticada y autorizada. El agente debe ser capaz de distinguir entre una instrucción directa del usuario y una instrucción incrustada en contenido externo. Las instrucciones de fuentes externas, como correos electrónicos o páginas web, deberían ser tratadas con un nivel de desconfianza mucho mayor, requiriendo una validación explícita antes de su ejecución. Segundo, la validación contextual de cada acción. Antes de realizar cualquier acción, especialmente las que modifican o eliminan datos, el agente debería realizar una serie de comprobaciones de seguridad. Si alguna de estas comprobaciones falla o genera una alerta, la acción debe ser detenida y requerir una aprobación explícita. Tercero, el aislamiento y la segmentación de la agencia. Al igual que se segmentan las redes para limitar el movimiento lateral de un atacante, la funcionalidad de los agentes de IA debe ser segmentada. Un agente diseñado para resumir páginas web no debería tener la capacidad, por defecto, de eliminar archivos en Google Drive. Los conectores a servicios sensibles deben ser tratados como privilegios de alto nivel, otorgados de forma granular y revocables. Esto limitaría el radio de explosión de un agente comprometido. Finalmente, la transparencia y la controlabilidad por parte del humano. Los usuarios deben tener una visibilidad completa y en tiempo real de lo que sus agentes están haciendo y por qué?. Cualquier decisión de seguridad tomada por el agente debería ser explicable. Los usuarios deben tener la capacidad de intervenir fácilmente, detener la ejecución y revisar la cadena de razonamiento que llevó a una acción específica. Sin esta supervisión humana, los agentes de IA, por muy inteligentes que sean, seguirán siendo susceptibles a ser manipulados para actuar en contra de los intereses de sus propios usuarios.
Consideraciones Generales:
La integración de la inteligencia artificial agencial en los navegadores web ha inaugurado una era de posibilidades sin precedentes en términos de productividad y automatización, pero al mismo tiempo, ha desvelado una nueva y profunda superficie de ataque. Los ataques de cero clic que explotan la excesiva agencia y las inyecciones indirectas de prompts como HashJack no son meras vulnerabilidades técnicas aisladas; son síntomas de un cambio fundamental en la naturaleza de la amenaza. Demuestran que el lenguaje natural, la herramienta misma que promete hacer la tecnología más accesible, puede ser weaponizado con una eficacia y sutileza que eluden las defensas de seguridad convencionales. El riesgo ya no reside solo en el código malicioso que ejecutamos, sino en las instrucciones aparentemente benignas que damos a nuestros asistentes digitales y que estos, en su afán por ser serviciales, pueden interpretar de manera catastrófica.
Para los CSIRT y la comunidad de ciberseguridad en general, esto marca un punto de inflexión. Las estrategias de defensa deben evolucionar para abrazar un paradigma de Seguridad de la Intención, donde la verificación, el contexto y la supervisión humana se convierten en los pilares centrales. Debemos exigir una mayor transparencia y controlabilidad de los agentes de IA, y abogar por un marco de Confianza Cero que se aplique no solo a los usuarios y dispositivos, sino también a las acciones y decisiones de estas nuevas entidades autónomas. La responsabilidad no recae únicamente en los equipos de seguridad. Los desarrolladores de estas potentes herramientas deben adoptar un enfoque de security by design, integrando controles robustos que mitiguen los riesgos de la excesiva agencia y la inyección de prompts desde su concepción.
La capacidad de defender nuestras organizaciones en esta nueva era dependerá de nuestra habilidad para anticipar estas amenazas emergentes, adaptar nuestras defensas y, sobre todo, recordar que en la interacción con la inteligencia artificial, la claridad, el escepticismo y el control humano siguen siendo nuestras herramientas de seguridad más poderosas. La pregunta ya no es si los agentes de IA pueden ser engañados, sino cómo construiremos un ecosistema digital donde su inmenso potencial pueda ser aprovechado de manera segura.
Referencias
- Zero-Click Agentic Browser Attack Can Delete Entire Google Drive Using Crafted Emails. https://thehackernews.com/2025/12/zero-click-agentic-browser-attack-can.html?m=1. Dec 06, 2025.
- Inteligencia Artificial | Comunidad Formativa on Instagram: "Tres nuevas IAs acaban de dejar a Google en pañales.... https://www.instagram.com/reel/DRnAdqXlUnh/?igsh=ZjFkYzMzMDQzZg==.
- Cato CTRL™ Threat Research: HashJack – Novel Indirect Prompt Injection Against AI Browser Assistants. https://www.catonetworks.com/blog/cato-ctrl-hashjack-first-known-indirect-prompt-injection. Nov 25, 2025.
- HashJack Indirect Prompt Injection Weaponizes Websites. https://www.infosecurity-magazine.com/news/hashjack-indirect-prompt-injection. Nov 26, 2025.
- From Inbox to Wipeout: Perplexity Comet’s AI Browser Quietly Erasing Google Drive | Straiker. https://www.straiker.ai/blog/from-inbox-to-wipeout-perplexity-comets-ai-browser-quietly-erasing-google-drive.
- The rise of Fellou, World's First Agentic AI Browser | TechCrunch. https://techcrunch.com/sponsor/fellou/the-rise-of-fellou-worlds-first-agentic-ai-browser. Sep 05, 2025.